Date: Fri, 11 Mar 2016 22:31:09 +0000
Good afternoon all,
About second step handling and editing source.f:
I had imagined first solution (loading all particles each event) would return a more realistic simulation, because it ensures all particles from first step are going to second step. Using the second solution with FLRNDM(DUMMY), some particles could be launched more than others, since they are randomly chosen.
I've tried this second way, however I come across a problem: how to move back the pointer of READ() function. For example, imagine the first random tells to Fortran "get the 45ª line", so, it'll take such line; in the next iteration, if the random raffle "13", Fortran will not read 13ª line, but 58ª and, after some iterations, READ() will reach the end of the file, because it does not start from the beginning. So, what I did was not using FLRNDM(DUMMY), but just READ() in order to read the next line of the file each iteration. This way, the number of primaries in the second step will be limited to the number of lines in the input file; but, at least it's "working" now.
About need two steps:
The answer whether I need two steps depends on how much time I'll be saving. It seems to me that It will be shorten by half. However this judgement takes me to another doubt (I hope the last for this subject):
After all, when we work with N spawns and P primaries, isn't the simulation divided in P/N primaries by core?
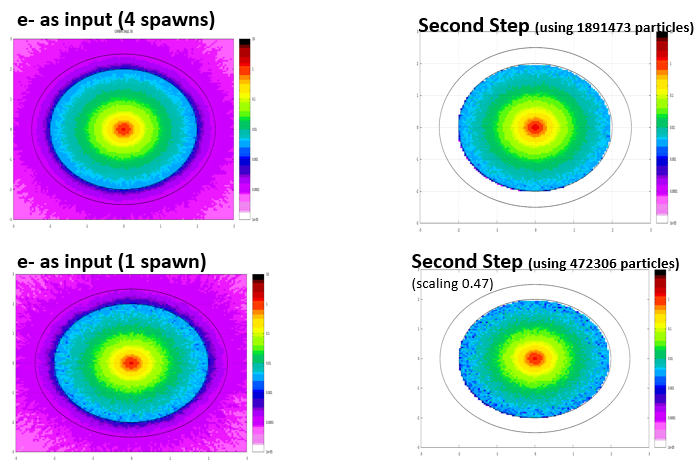
- First step using 1.E6 primaries with just 1 spawn and 1 cycle generated an output file with 472 306 particles crossing regions set at USERDUMP/mgdraw.
- First step using 1.E6 primaries with 4 spawns and 1 cycle generated 4 output files with 472 306 + 472 701 + 474 139 + 472 352 = 1 891 498 particles. I expected it would generate 472306/4 = 10984 particles by core to be concatenated next. If each spawn uses all 1.E6 primaries, using spawn is useful "only" to get better statistic, not for speeding up, right? But isn't it already covered by the number of cycles?
- Second step using 472306 particles took 1h10min (4 cycles, 5 spawns)
- Second step using 1891498 particles took 4h50min (4 cycles, 5 spawns)
- A single step simulation of this case using 1.E6 primaries took ~2h30min (4 cycles, 5 spawns);
So, the way I see it:
A. using two steps for this case means cutting simulation time by half.
B. For scaling, I need multiply the final result by 472306/1.E6 = 0.47 no matter how many primaries I use.
C. That simulation of a second step with 1891498 particles is, actually, equivalent to a 4.E6 primaries single simulation (but I didn’t test).
About compilation inside Flair:
I can compile new executables only when I use that codes on terminal. When I try do it use the tab "Compile" and the option "Build" inside Flair interface; it shows errors mentioning g77. But ok, perhaps I'm not using it right.
Attached file: USRBIN comparing Photon Flux in the same region in a single-step simulation and in the 2nd step :-)
Once more, thanks too much for patience, time and help.
Marlon
-----Mensagem original-----
De: Francesco Cerutti [mailto:Francesco.Cerutti_at_cern.ch]
Enviada em: quinta-feira, 10 de março de 2016 12:48
Para: Marlon Saveri Silva <marlon.saveri_at_lnls.br>
Cc: Mao, Stan <mao_at_SLAC.Stanford.EDU>; fluka-discuss_at_fluka.org
Assunto: Re: RES: [fluka-discuss]: RES: Splitting FLUKA runs
Hi Marlon,
I see a main conceptual flaw here [apart from the fact that one should always ask him/herself if he/she really needs two steps].
One (right) thing is to dump million particles in the first step and then read all of them at initialization in your second step source.f. If you properly set the dimension of your source arrays, you do not meet any problem with that.
Another (wrong) thing is to load, as you do, ALL particles at EACH second step primary event. This way you have a first step primary generating on average, according to what you wrote, 0.47 dumped particles, and in each second step history you want to load million particles! This makes no sense and certainly breaks the stack size, that by the way you cannot alter (as reminded many times on this list, one cannot change the parameters in the included files of $FLUPRO/flukapro, since the FLUKA library has been precompiled with the distributed values). So you should rather sample ONE particle at a time from your arrays: if you have read NLINES particles, then choose ISAMPL = FLRNDM (DUMMY) * NLINES ISAMPL = ISAMPL + 1 and take the relevant properties of the particle #ISAMPL (PART(ISAMPL),X(ISAMPL), etc), removing the illogical cycle
DO 40 MYCOUNT=1, NLINES
NPFLKA = NPFLKA + 1
Then, what matters for the second step error (without forgetting that one should also have a clue on the first step error) is number of (second
step) primaries times number of cycles, which means total statistics (still you need at least a few cycles to let FLUKA postprocessing tools evaluate the statistical error, and let you judge it).
Finally, from what you wrote, I cannot understand what is your problem with the compilation inside Flair
Kind regards
Francesco
**************************************************
Francesco Cerutti
CERN-EN/STI
CH-1211 Geneva 23
Switzerland
tel. ++41 22 7678962
fax ++41 22 7668854
On Wed, 9 Mar 2016, Marlon Saveri Silva wrote:
>
> Dear Vittorio and all,
>
>
>
> I had misunderstood a comment about remove all statements in MGDRAW
> ENTRY. Thanks to your answer, now mgdraw.f (attached) is compilling
> and linking!!!
>
>
>
> The next step was edit source.f and it has seemed to be right,
> however when I compared photon fluence in the 1st step with photon
> fluence in the 2nd step in a same section it was a little different
> (ComparingSteps1E4.PNG).
>
>
>
> When I repeat using more primaries, difference still occurs and
> after some hours I realized the source.f is able to read only the
> first 40000 lines from USERDUMP output file, because parameter NLINES
> is limited to 40000.
>
>
>
> It’s a big problem, because I need do such simulation using at
> least 1E8 primaries (in this case, each primary generates 0.47
> particles in that section… So I need to use a file with 4.7E6 rows).
>
>
>
> I imagined it happens because MFSTCK parameter inside the file
> (DIMPAR) is set as 40000. Therefore, I tried change MFSTCK to
> 50000000, but after this I couldn’t compile my new source.f anymore.
> When I changed MFSTCK to
> 50000 it had compiled, however Flair simulation finished with
> TIMED.OUT
>
>
>
> It’s using gfortran (export FLUFOR=gfortran); otherwise source.f
> was not compiling; by the way, I suppose that’s the reason I can’t
> compile inside Flair.
>
> Linux version file: “Linux version 3.19.0-47-generic
> (buildd_at_lgw01-19) (gcc version 4.8.2 (Ubuntu 4.8.2-19ubuntu1) ) […]”
>
>
>
> Finally, about second step, since each primary means NLINES
> particles (and
> 1 primary from 1st step); in order to have a smaller error, is it
> better use more primaries or more cycles?
>
>
>
> ======================================================================
> =====
> ======================================================================
> =====
> ====
>
> Some notes (summary) about editing mgdraw.f and source.f if someone
> intent to use in the future:
>
>
>
> 1. Use CHARACTER*8 MRGNAM, NRGNAM in order to use region names
> instead of numbers
>
> 2. I typed WRITE(88,*) JTRACK,XSCO,YSCO,
> ZSCO,CXTRCK,CYTRCK,Ecin,WTRACK in just one line, without spaces
> because FORTRAN is limited to 72 characters by line
>
> 3. This way, USERDUMP generates a file with “spaces” as separator, but
> source.f needs “tab”. Therefore it needs be converted. It can be made
> using excel, however excel has a limited number of rows.
>
> 4. Likewise, USERDUMP generates an output using E as 10^ (e.g: 100 =
> 1.0E+2); the input works with D (100 = 1.0D+2)
>
> 5. Besides that, if 1st step is made using more than 1 spawn, output
> files need be concatenated
>
> 6. Type of particle needs be defined as INTEGER instead of DOUBLE
> PRECISION;
> i.e.: INTEGER PART(NLINES)
>
> 7. To link mgdraw.f, use Vittorio suggestion:
>
> $FLUPRO/flutil/fff $FLUPRO/usermvax/mgdraw.f
>
> $FLUPRO/flutil/lfluka -m fluka $FLUPRO/usermvax/mgdraw.o
>
> 8. To compile TwoStepsSource.f, use:
>
> cd $FLUPRO
>
> export FLUFOR=gfortran
>
> $FLUPRO/flutil/fff $FLUPRO/flutil/TwoStepsSource.f
>
> $FLUPRO/flutil/lfluka -o TwoStepsSource -m fluka
> $FLUPRO/flutil/TwoStepsSource.o
>
> 9. It’s easier for me open .dat using OPEN Card instead of using “open”
> inside source.f
>
>
>
>
>
> De: Vittorio Boccone [mailto:dr.vittorio.boccone_at_ieee.org]
> Enviada em: sábado, 5 de março de 2016 21:12
> Para: Marlon Saveri Silva <marlon.saveri_at_lnls.br>
> Cc: Mao, Stan <mao_at_slac.stanford.edu>; fluka-discuss_at_fluka.org
> Assunto: Re: [fluka-discuss]: RES: Splitting FLUKA runs
>
>
>
> Hi Marlon, seems you have heavily changed the mgdraw removing SODRAW,
> ENDRAW etc.. therefore you custom mgdraw cannot anymore replace the default one.
> This two lines should do the compilation
>
>
>
> :~/Software/fluka-list$ $FLUPRO/flutil/fff my_mgdraw.f
>
> :~/Software/fluka-list$ $FLUPRO/flutil/lfluka -m fluka my_mgdraw.o
>
>
>
>
>
> Plus you might have several libraries missing.
>
> Which Linux version and which gfortran (or g77) version are you using?
>
> Best,
>
> V.
>
>
>
> On 04 Mar 2016, at 21:08, Marlon Saveri Silva
> <marlon.saveri_at_lnls.br> wrote:
>
>
>
> Dear FLUKA experts,
>
> Here I am again. :/
>
> This solution (making a two steps simulation) was suggested at the
> topic "Estimating hardware configurations for bremsstrahlung
> simulations",
>
> In my last e-mail, I present a big mistake trying to score a lot of
> values (energy, type, position, etc) using a combination of USRBDX,
> USRBIN and FORTRAN programming with a wrong Gaussian function.
>
> The right solution for doing this two-steps simulation is using
> USERDUMP card according to some publications/discussions:
>
> https://www.fluka.org/free_download/course/triumf2012/Workshop/Laxdal.
> http://www.fluka.org/web_archive/earchive/new-fluka-discuss/6806.html
> http://www.fluka.org/web_archive/earchive/prova/0395.html
>
> So, I introduced USERDUMP, edited mgdraw.f (attached) and I typed "
> $FLUPRO/flutil/fff $FLUPRO/usermvax/mgdraw.f" to create mgdraw.o.
>
> It works. So, the next step here is understand why I can not generate
> the executable using any of the codes below (found on internet) and
> understand how to read and concatenate such output files.
> Nevertheless, the existence of this BXDRAW function left me quite
> optimistic.
>
> $FLUPRO/flutil/lflukac -m fluka -C $FLUPRO/usermvax/usrini.f
> $FLUPRO/usermvax/usrout.f $FLUPRO/usermvax/mgdraw.f -o flukaseamu
> $FLUPRO/flutil/lfluka -m fluka -o flukamy $FLUPRO/usermvax/mgdraw.o
> $FLUPRO/flutil/lfluka -o mgdraw $FLUPRO/usermvax/mgdraw.f
> $FLUPRO/flutil/lfluka -o $FLUPRO/MyFluka -m fluka
> $FLUPRO/flutil/s160302.o $FLUPRO/usermvax/mgdraw.o
>
>
> Thanks again,
> Marlon
>
>
> Some errors showed:
>
> /opt/fluka/libflukahp.a(mgdraw.o): In function `mgdraw_':
> /home/alfredo/fluprogfor/usermvax/mgdraw.f:6: multiple definition of
> `mgdraw_'
> /tmp/cceb4mg7.o:/opt/fluka/usermvax/mgdraw.f:6: first defined here
> /opt/fluka/libflukahp.a(mgdraw.o): In function `bxdraw_':
> /home/alfredo/fluprogfor/usermvax/mgdraw.f:105: multiple definition of
> `bxdraw_'
> /tmp/cceb4mg7.o:/opt/fluka/usermvax/mgdraw.f:67: first defined here
> /usr/bin/ld: cannot find -lmathlib
> /usr/bin/ld: cannot find -lpawlib
> /usr/bin/ld: cannot find -lgraflib
> /usr/bin/ld: cannot find -lgrafX11
> /usr/bin/ld: cannot find -lpacklib
> /usr/bin/ld: cannot find -lkernlib
> collect2: error: ld returned 1 exit status
> ------------------------------------------------------
>
> gfortran: error: -m: No such file or directory
> gfortran: error: fluka: No such file or directory
> gfortran: error: -o: No such file or directory
> gfortran: error: flukamy: No such file or directory
> ------------------------------------------------------
>
> collect2: error: ld returned 1 exit status
> ------------------------------------------------------
>
> /opt/fluka/libflukahp.a(mgdraw.o): In function `mgdraw_':
> /home/alfredo/fluprogfor/usermvax/mgdraw.f:6: multiple definition of
> `mgdraw_'
> /opt/fluka/usermvax/mgdraw.o:/opt/fluka/usermvax/mgdraw.f:6: first
> defined here
> /opt/fluka/libflukahp.a(mgdraw.o): In function `bxdraw_':
> /home/alfredo/fluprogfor/usermvax/mgdraw.f:105: multiple definition of
> `bxdraw_'
> /opt/fluka/usermvax/mgdraw.o:/opt/fluka/usermvax/mgdraw.f:67: first
> defined here
> /usr/bin/ld: i386 architecture of input file
> `/opt/fluka/flutil/s160302.o' is incompatible with i386:x86-64 output
> /opt/fluka/flutil/s160302.o: In function `source_':
> /opt/fluka/flutil/s160302.f:133: undefined reference to `s_wsle'
> /opt/fluka/flutil/s160302.f:133: undefined reference to `do_lio'
> /opt/fluka/flutil/s160302.f:133: undefined reference to `do_lio'
> /opt/fluka/flutil/s160302.f:133: undefined reference to `e_wsle'
> /opt/fluka/flutil/s160302.f:159: undefined reference to `s_rnge'
> /opt/fluka/flutil/s160302.f:159: undefined reference to `s_rnge'
> /opt/fluka/flutil/s160302.f:159: undefined reference to `s_rnge'
> /opt/fluka/flutil/s160302.f:159: undefined reference to `s_rnge'
> /opt/fluka/flutil/s160302.f:159: undefined reference to `s_rnge'
> =================================================================
>
> USERDUMP configurations: Type Dump, What Complete, Unit 96, Score
> Local Losses
>
> *...+....1....+....2....+....3....+....4....+....5....+....6....+....7
> ....+
> ....
> USERDUMP 100. 96. 3.
> Dump
>
>
> -----Mensagem original-----
> De: Mao, Stan [mailto:mao_at_slac.stanford.edu]
> Enviada em: sexta-feira, 4 de março de 2016 15:06
> Para: 'fluka-discuss_at_fluka.org' <fluka-discuss_at_fluka.org>
> Cc: Marlon Saveri Silva <marlon.saveri_at_lnls.br>
> Assunto: RE: Splitting FLUKA runs
>
> Please help Marlon on his question.
> Thanks
> Stan
>
> -----Original Message-----
> From: Mao, Stan
> Sent: Friday, March 04, 2016 10:05 AM
> To: 'fluka-discuss_at_fluka.org'
> Cc: 'marlon.saveri_at_lnls.br'
> Subject: FW: Splitting FLUKA runs
>
>
>
> -----Original Message-----
> From: Marlon Saveri Silva [mailto:marlon.saveri_at_lnls.br]
> Sent: Friday, March 04, 2016 5:27 AM
> To: hvincke_at_slac.stanford.edu; Mao, Stan; Rokni, Sayed H.
> Cc: Roberto Madacki; MARILIA LISBOA DE OLIVEIRA; Beamlines Common
> Systems
> Subject: Splitting FLUKA runs
>
> Dear Mr. Vincke, Mao and Rokni,
>
>
>
> In December 2003 there was a very interesting
> publication from SLAC (SLAC-PUB-10010 - FLUKA Calculations for the
> Shielding Design of the SPPS Project at SLAC), in which FLUKA
> simulation were made in order to determine shielding.
>
> A greatly important point is quoted in the 4th page:
> "the calculations were split into two runs. In a first set of runs
> (called RUN 1) information of particles reaching a virtual plane
> outside the FFTB north wall was stored on a file" and such information
> included: "number of total primaries, total weight of the primary
> praticles, energy, particle type, weight, co-ordinates [and] direction
> cosines".
>
> I've been working on FLUKA simulations in order to
> estimate life of some equipment subject to high dose inside a beamline
> and, recently, aiding the Radiological Protection Group with other
> calculations for Sirius beamlines.
>
> Perhaps you have seen my topic at FLUKA-discuss forum
> some days ago about the difficulty in getting faster simulations and
> how to relate time and hardware configuration. One of the indicated
> solution is splitting the simulation in two or more parts as you did
> in your work thirteen years ago.
>
>
>
> In a perfect world, there would be a card in FLUKA (RUN1) wherewith we
> just draw a plane and it would give us a file containing all
> information to be exported as an input file for RUN2 (it would make me
> very happy).
>
> I've started trying an alternative way using USRBDX
> card to get spectrum of photons, using USRBIN card to get the position
> distribution in this transversal section of the pipe and, finally,
> trying to generate a FORTRAN code inside source.f (based on random
> numbers) to create an input for RUN2 similar to those outputs of RUN1.
>
> However, I'm having troubles programming it and the new
> input for RUN2 is different from RUN1 output (as you can check in the
> attached example). Moreover, this solution don't give me information
> about particle type, weight, direction cosines and I'm not sure about
> the best way to select energies (random vs import from a discrete
> table).
>
>
>
> Therefore, if you may share, I'd like to understand how have you done
> such splitting.
>
>
>
> Thanks,
>
>
>
> Marlon Saveri Silva
>
> Mechanical Engineer
> Beamlines Instrumentation and Support Group - SIL Brazilian
> Synchrotron Light Laboratory- LNLS - CNPEM
> + 55 (19) 3512-2490
>
> + 55 (19) 99478-8097
>
>
>
> <mgdraw.f>
>
>
>
>
>
__________________________________________________________________________
You can manage unsubscription from this mailing list at https://www.fluka.org/fluka.php?id=acc_info
(image/png attachment: Output1_vs_Input2.PNG)